이런 사례는 2020년 한 업체가 출시한 AI 챗봇 ‘이루다’가 성희롱 발언과 소수자에 대한 편견을 담은 혐오표현을 내뱉었던 사건에서 잘 알 수 있어요. 이루다가 학습한 데이터는 메신저 서비스를 통해 확보한 연인 간 대화 100억 건이었는데, 학습 과정에서 거르지 않은 내용이 있었던 겁니다. 100억 건의 대화를 어떻게 일일이 검토할까 싶기도 하지만, 그렇다고 문제를 방치해선 안 될 테니 세심한 대책이 필요할 거예요. 그렇지 않으면 여성을 비롯한 소수자에 대한 부정적 영향에 빅데이터가 일조하는 것이니까요.
또 다른 사례로는 아마존에서 개발하여 시범 운영했던 인공지능이 채용 과정에서 여성을 차별했던 사건도 있어요. 기존 10년간 지원자 이력서 내용 등을 학습한 이 시스템은 2014년부터 운영되었어요. 그런데 학습된 과거 자료에는 남성 지원자 정보가 압도적으로 많았기 때문인지 여성 지원자에게 감점을 주는 문제가 있었습니다. 결국 아마존은 201년 이 인공지능 채용 시스템을 폐기했어요. 단지 여성이라는 이유로 채용되지 못하는 사례가 잘못된 데이터로 인해 발생한 겁니다.
그런가 하면 특정 성별에 대한 데이터가 아예 없을 수도 있습니다. 지난 9월 신당역에서 발생한 사건을 기억하실 겁니다. 스토킹 가해자가 피해자를 살해한 사건이 있었지요. 이처럼 스토킹 범죄로 인해 사망하는 일이 많이 있음에도 이에 대한 데이터가 수집되지 않고 있습니다. 이런 현상을 두고 ‘젠더 데이터 공백’이라고 부릅니다. 즉 여성의 데이터가 제대로 수집되지 않는 현상을 일컫는 것이지요. 범죄 통계는 경찰, 검찰 등에서 집계하는데, 이들 기관이 손을 놓고 있는 사이 결국 시민단체인 한국여성의전화가 ‘분노의 게이지’라는 프로젝트를 통해 나름의 자료를 내놓고 있는 상황이에요.
올해 3월에 발표된 <2021년 분노의 게이지>에 따르면, 언론 보도를 기준으로 과거 또는 현재에 친밀한 관계 또는 일방적 요구를 하는 관계에 있는 남성으로부터 살해된 여성의 수는 103명, 살인미수에 그친 경우는 216명에 이릅니다. 이것은 언론에 보도된 제한된 자료만을 바탕으로 했기 때문에 사실 이보다 더 많은 피해사례가 있을 거예요. 이런 젠더 데이터 공백 상태에서 아무리 빅데이터를 분석한들 좋은 정책이 나올 리 만무합니다.

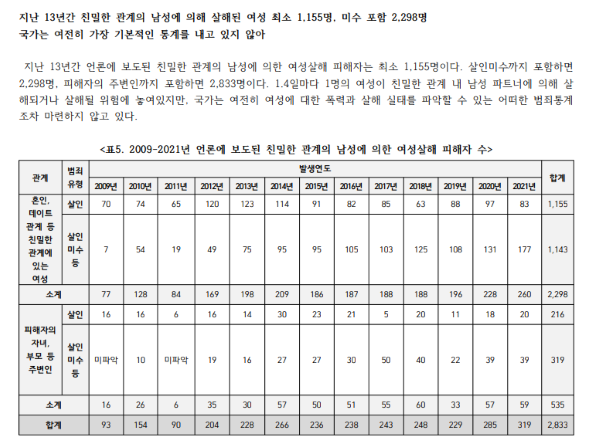 [그림 3] 한국여성의전화에서 발행한 <2021년 분노의 게이지> 중 최근 13년간 여성살해 피해자 수 통계와 설명 (출처: 해당 보고서에서 갈무리)
[그림 3] 한국여성의전화에서 발행한 <2021년 분노의 게이지> 중 최근 13년간 여성살해 피해자 수 통계와 설명 (출처: 해당 보고서에서 갈무리)